
Coding practices should be in place to maintain a consistancy among software projects to enforce a disciplines which improves the quality of software, improves reuseability due to more generic interfaces and good documentation, results in software with fewer bugs which is easier to use and maintain.
- File Names:
- There should be one include file for each source code file. Each include file should describe a single class or tightly integrated set of classes. The general guideline is for include (.h and .hpp) files to contain definitions and NOT instantiations. Thus the include file can be used in multiple files. The source file (.C or .cpp) defines code which when compiled gets loaded into memory. It instantiates definitions defined in the include file. For example, a class definition would be contained in the ".hpp" include file. A global variable would be instantiated in the ".cpp" file and NOT the ".hpp" file. This is because the global variable would be defined more than once if the include file was used more than once. An "extern" statement is appropriate for an include file as it does not declare memory for the variable but just recognises its existance.
- File name should reflect the class name. While the class name typically starts with a capital letter, the include file and source files typically begin with lower case letters. i.e. file classBase.hpp will contain the definition of ClassBase{} and classBase.cpp will contain the source code to it's functions.
- Class names should follow the following format: CXxClassID where "Xx" refers to the component. (i.e. Mn main, Fm File manager, Cp command processor) The first character of each word shall be capitalized. Leave off the "C" prefix when naming the file.
- When referring to an include file within either another include file or source file, do NOT include the full path. This avoids portability problems created by operating system dependent methods of referencing directory paths. Use compiler command line flags to include the path. (i.e. -I/path-name)
- Use double quotes ("") for all project include files and angle chevrons (<>) for include files provided by the operating system or compiler.
- If burning ISO CD's, remember it is limited to file names of up to 30 characters.
- To ease use with scripts and make files, file names (and directory paths) should not contain blanks, parentheses "(", or crazy characters not supported by a majority of operating systems.
- File formats:
- Line termination: For cross platform development, keep the "^M" line terminator out of files. They can be removed by the following:
- Command: dos2unix filename.cpp
- In vim: :1,$ s/{ctrl-V}{ctrl-M}//
For more see the YoLinux.com Subversion tutorial. - If using MS/Visual studio, add a blank line at the end of the file with at least one blank space as this IDE may remove the perceived Unix "end-of-file" marker (ctrl-D). For more see the YoLinux.com MS/Visual C++ best practices guide.
- Line termination: For cross platform development, keep the "^M" line terminator out of files. They can be removed by the following:
- File headers:
- File headers should include copyright statements, distribution licensing references and reflect corporate practices. For example, if source code is released under the GNU license it should be stated as such. If the file contains corporate proprietary material, it should be stated as such. The segragation of such code into separate files is very important if the licensing, release practices for the file or copyrights are different.
- Comments shall be placed at the top of each file stating the name of the file
and comments on the file contents. Comments should be directed towards the
users of the class contained in the file.
See below: File Header Comments
- Header files:
- C++ header files often use the suffix ".hpp" while "C" header files use ".h" suffix.
- Use the preprocessor to check for multiple inclusions.
#ifndef CLASS_NAME_H #define CLASS_NAME_H ... .. #endif - Reduce the number of #include files in header files.
It will reduce build times. Instead, put include files in source code files and use forward declarations in header files.
If a class in a header file does not need to know the size of a data member class or does not need to use the class's members then forward declare the class instead of including the file with #include.
To avoid the need of a full class declaration, use references (or pointers) and forward declare the class.
Example of forward declaration:
[Potential Pitfall]: STL collections (like std::list and std::vector) and typedefs can not use forward declarations and thus #include must be used.class ClassName; - If C functions will be called from C++, then C include files will use the following declaration:
#ifdef __cplusplus extern "C" { #endif ... .. C function declarations .. ... #ifdef __cplusplus } #endif - Avoid the use of "namespace" in the ".hpp" include file. If the file is included in source code the programmer may no longer use variables defined in the namespace and may experience variable name clash.
- Classes and Structs:
- Standard practice is for class and struct definitions to begin with a capital letter. Base classes will often have the suffix "Base" appended to the class name. Be sure to add virtual (not pure virtual thus not "=0") to the base class destructors so both destructors are called.
- Example Class contents:
class ClassName { public: // Constructors: // Destructor: // Functions: modifiers (set), selectors (get) // itterators: // Attributes visible by scope of instantiation and use protected: // Attributes visible to descendents private: // Local attributes };
- Machine dependent code shall, if possible, be placed in a separate file so that
it may ease porting tasks.
- Functions/subroutines:
- Length: It makes no sense to set a rule or hard limit on the length of a function. A human should be able to fully understand the complexity of a single function. If one can't, then it needs to be broken down into a smaller understandable size. It makes no sense to break a 3000 line function into smaller components if all it consists of is a massive case/switch statement which can be grasped upon first viewing. Complex algorithms should be broken up into understandable units and may be too long at 50 lines of code. Thus the length of a function requires common sense more than a rule which sets a hard limit.
- List functions in ".cpp" file in the same order in which they are declared in the ".hpp" class declaration.
- Names: Use complement names for complement functions: get/set, add/remove, create/destroy, start/stop, insert/delete, increment/decrement, begin/end, first/last, up/down, min/max, next/previous, open/close, show/hide, suspend/resume, etc.
- Use keyword "const" to indicate that a variable or function parameter does not change.
- Use capital leters with an underscore used to separate words for macro constants and enumerations.
- Use a single capital letter to denote the start of a new word in the
variable, class or function name.
Example: thisIsAnExample - Function names should begin with a lower case letter.
- Class definitions begin with a capital letter. The "C" prefix is
"Hungarian" notation as noted below. The instantiation should begin with
a lower case letter.
Example: CAbcXyz abcXyz
class ClassName
{
enum Month { January, February };
}
Month tmpMonth = ClassName::January;
- Operators should have a space on wither side of them: +, -, <. >, =, ==, ...
- Use spaces for indentation. Don't use tabs as different IDEs and editors may treat them differently. Also see the YoLinux.com MS/Visual C++ best practices tutorial to avoid cross platform pitfalls.
if( longVariableNameAbc < longVariableNameDef &&
longVariableNameIjk < longVariableNameXyz)
{
}
Camel-case is the practice of changing the letter to upper case to denote the start of a new word. This allows the name to be shorter because no separator character (i.e. "_" used between words.) The Camel-case practice uses a "_" separator between upper case constants used in words.
Examples:
- VariableForTheBlueTeam
- variableForTheBlueTeamInstantiation
- SPAM_Eliminator
"Hungarian" prefixes: Some of these are discussed in the book "Code Complete" and others I have seen in corporate coding standards. While these are prefixes (beginning of name) I have also seen some used as suffixes (end of name).
| Prefix | Description |
|---|---|
| m_ my_ |
Variable is a member of class. Some use the prefix "my" for class member variables and "our" for class member static variables. (Also "m" and "ms" for member and member-static) I have also seen the use of "_" as both a prefix and as a suffix to denote a class member variable. If using mixed languages remember that many FORTRAN compilers use a "_" suffix. Due to C++ name mangling there will probably be no conflict when using this notation. It is a common practice but theoretically could pose a problem with mixed languages. See Mixing FORTRAN and C YoLinux tutorial. |
| _ (underscore) |
Note: Dangerous when mixing C with FORTRAN as FUNCTION subroutines as suffixed with "_" in the object code. See nm to view object symbols. See the g77/f77 compiler flag "-fno-underscore". |
| __ | Marks an use as extension to ANSI C++. Often not
compiler independant. Usually reserved for use by compiler writers so
it is best to avoid the double underscore.
Note: Be careful when mixing with FORTRAN as "__" is often generated in FORTRAN object symbol names. See the f77 compiler flag "-fno-second-underscore". Also used in Microsoft "Managed C++" directives. |
| a | array |
| c n |
count / number of |
| cb | count bytes / number of bytes |
| d | Data type double |
| dw | Data type double word |
| e | an enumeration or element of an array |
| b f is has should |
boolean (flag) Example: isFound Note: accessor functions can also use these same prefixes: bool isBoolean{ return mBoolean; } |
| g_ g gbl Gbl |
global variable. Also used is the "::" operator. i.e. ::variable |
| s s_ |
Static variable |
| h | handle |
| i | index to an array or STL iterator |
| l | long data type. i.e. "long int" |
| p ptr |
pointer. Sometimes "Ptr" used as suffix. |
| lp | pointer to long data type |
| ch | C character |
| sz | Zero terminated string. char[] |
| str | C++ GNU template data type "string" |
| u | unsigned |
| ev | event |
| min | Lowest value |
| first | First element |
| lim | array limit |
| cmd | Command |
| cmp | Compare |
| init | Initialize |
| intr | Interrupt |
| msg | Message |
| rx | Recieve |
| tx | Transmit |
| C | Prefix for a Class name. Notation used by Microsoft MFC. Example: CAbcXyz abcXyz Note: The instatiation begins with a lower case letter while the class definition begins with a capital letter. |
| _t _Type |
Type definition (typedef - suffix). Prefix with capital letter. |
| _Enum | Enumeration type definition suffix. |
| _ds | Data structure suffix. |
Hungarian Examples:
- ppachVarName: pointer to a pointer of an array of characters.
- m_ppachVarName: class member variable which is a pointer to a pointer of an array of characters.
This is usually set as a project or corporate standard and include copyrights,
statements of ownership, trade secret statements, author's name,....
For example:
// ----------------------------------------------------------------------------
/**
File: ProjectXXX.suffix
System: Super Product X
Component Name: Project X, Module B
Status: Version 1.0 Release 1
[Note: depricated practice. CM systems like Subversion will maintain file history.]
Language: C++
License: GNU Public License
or other... i.e.
Licensed Material - Property of Mega Corp
(c) Copyright Mega Corp 2008
Address:
Mega Corp, Super Product X Division
134950 Sepulveda Blvd.
Los Angeles CA 90211
Author: John Doe
E-Mail: John.Doe@MegaCorp.com
[Note: Not required if using CM systems like Subversion which maintain author info and file history.]
Description: Header file for Project X
This file contains the defined types for Project X
This is sometimes called the "Abstract" and may be
followed by a section called "Notes".
Limitations: bla bla bla
Function: 1) bla bla bla
2) bla bla bla
3) bla bla bla
Database tables used:
Thread Safe: No
Extendable: No
Platform Dependencies: None (i.e.: Linux/Intel, IRIX/Mips, Solaris/SPARC)
Compiler Options: -lm
Change History: (Sometimes called "Revisions")
[Note: this is no longer necesary if using a CM system like Subversion.
Subversion will hold check-in comments and note the author of the change.]
Date Author Description
*/
// ----------------------------------------------------------------------------
...
..
.
..
...
// ----------------------------------------------------------------------------
/**
Routine: NameOfRoutine()
Inputs:
Arguments:
Externals:
Others:
Outputs:
Arguments:
Externals:
Returns:
Errors:
Routines Called:
*/
// ----------------------------------------------------------------------------
- Comments should NOT contain code as it may get out of sync with the code itself.
- CM systems handle author (with email address), change history and date. No need to duplicate this information if CM is handling this for you.
- Version numbers can be embedded into checked out code by the CM system. No need for this to be performed manually if managed by CM.
- See dOxygen (below) for coding style used to comment function in/out parameters.
- ScanDoc: Perl script which scans C++ source code for specially-formatted comments and produces organized, indexed documentation.
scandoc home page - HeaderBrowser: Create documents from file headers
HeaderBrowser home page
dOxygen: cross-platform, JavaDoc-like documentation system for C++, Java, C, and IDL. DOxygen is included with the base release of most Linux distributions including Red Hat and SuSE. DOxygen tags support two basic format styles, \tagname or @tagname. The later is the Javadoc style which is shown in this tutorial.
Doxygen home page - doxygen freshmeat page
Example:
// $Id$
/**
* @file sourceFile.cpp
* Write description of source file here for dOxygen.
*
* @brief Can use "brief" tag to explicitly generate comments for file documentation.
*
* @author Me
[Note: depricated practice as CM systems like Subversion will maintain author info and blame logs.]
* @version 1.69
[Note: depricated practice as CM systems like Subversion will maintain file history and revision numbers.]
*/
// $Log$
/// Single line comment for dOxygen.
/**
Write description of function here.
The function should follow these comments.
Use of "brief" tag is optional. (no point to it)
The function arguments listed with "param" will be compared
to the declaration and verified.
@param[in] _inArg1 Description of first function argument.
@param[out] _outArg2 Description of second function argument.
@param[in,out] _inoutArg3 Description of third function argument.
@return Description of returned value.
*/
int
class::function(int _inArg1, int& _outArg2, int& _inoutArg3)
{
/// Single line comment for dOxygen.
}
Headings generated from tags:
| dOxygen tag | Rendering |
|---|---|
| @file file-name | Prints file-name as header of page. |
| @brief Brief description goes here. | Description appears in HTML document generated. |
| @details Brief description goes here. | Description of function which appears in HTML document generated. |
| @author name1 @author name2 |
Author:
|
| @version Version number | Version:
|
| @depricated explanation | Depricated:
|
| @class CAaaBbb | |
| @see FunctionA() | See also:
|
| @param[in] variableA DescriptionA @param[out] variableB DescriptionB @param[in,out] variableC DescriptionC Note: in and out are dOxygen specific and not used in Javadoc. |
Parameters:
|
| @return variableA | Returns:
|
| @bug Description of bug goes here | Bug:
|
| @warning Warning message goes here | Warning:
|
Full list of dOxygen Tags: http://www.stack.nl/~dimitri/doxygen/commands.html
Javadoc tags: http://java.sun.com/j2se/javadoc/writingdoccomments/
Note the difference between the dOxygen @throw and the Javadoc @throws tag.
dOxygen tags for @brief are not necessary if using JAVADOC_AUTOBRIEF (yes) mode. this will print the first line in a "/**" comment block as the brief description.
The tagged dOxygen comments are placed ahead of the C++ function, class or variable. Comments placed after a C++ entity can be tagged with "/**< ... */".
/** Comments on C++ function
...
...
*/
void classA::function_1( int variable1, /**< Comment on variable goes here. */
float variable2, /**< Comment on variable goes here. */
... ,
... )
{
...
Create a list:
/** List heading:
- Stuff on line 1
- Stuff on line 2
- Stuff on line 3
- Stuff on sub-line 1
- Stuff on sub-line 2
- Stuff on line 4
*/
Pages of documentation are defined by a group. You can specify the group directly using the tags:
- @defgroup
- @ingroup
The group is delimited by:
//@{
...
...
//@}
Documentation Main Page:
This is the home page or first page of the documentation which is defined by the "@mainpage" tag:
/** @mainpage ProjectX: bla, bla, bla
* @par Description:
* - Point 1 bla, bla, bla
* - Point 2 bla, bla, bla
* - Point 3 bla, bla, bla
*
* @par Next paragraph - more information:
* bla, bla, bla
* bla, bla, bla
*/
Display on main home page of documentation:
ProjectX: bla, bla, bla
Description:- Point 1 bla, bla, bla
- Point 2 bla, bla, bla
- Point 3 bla, bla, bla
bla, bla, bla
bla, bla, bla
Configuration file: project-name.cfg
Create template configuration file and tag descriptions with the command: doxygen -g project-name.cfg
# Doxyfile 1.4.4
# This file describes the settings to be used by the documentation system
# doxygen (www.doxygen.org) for a project
#
# All text after a hash (#) is considered a comment and will be ignored
# The format is:
# TAG = value [value, ...]
# For lists items can also be appended using:
# TAG += value [value, ...]
# Values that contain spaces should be placed between quotes (" ")
#---------------------------------------------------------------------------
# Project related configuration options
#---------------------------------------------------------------------------
PROJECT_NAME = "Project XXX"
PROJECT_NUMBER =
OUTPUT_DIRECTORY = project
CREATE_SUBDIRS = NO
OUTPUT_LANGUAGE = English
USE_WINDOWS_ENCODING = NO
# If the BRIEF_MEMBER_DESC tag is set to YES (the default) Doxygen will
# include brief member descriptions after the members that are listed in
# the file and class documentation (similar to JavaDoc).
# Set to NO to disable this.
BRIEF_MEMBER_DESC = YES
# If the REPEAT_BRIEF tag is set to YES (the default) Doxygen will prepend
# the brief description of a member or function before the detailed description.
# Note: if both HIDE_UNDOC_MEMBERS and BRIEF_MEMBER_DESC are set to NO, the
# brief descriptions will be completely suppressed.
REPEAT_BRIEF = YES
# This tag implements a quasi-intelligent brief description abbreviator
# that is used to form the text in various listings. Each string
# in this list, if found as the leading text of the brief description, will be
# stripped from the text and the result after processing the whole list, is
# used as the annotated text. Otherwise, the brief description is used as-is.
# If left blank, the following values are used ("$name" is automatically
# replaced with the name of the entity): "The $name class" "The $name widget"
# "The $name file" "is" "provides" "specifies" "contains"
# "represents" "a" "an" "the"
ABBREVIATE_BRIEF =
# If the ALWAYS_DETAILED_SEC and REPEAT_BRIEF tags are both set to YES then
# Doxygen will generate a detailed section even if there is only a brief
# description.
ALWAYS_DETAILED_SEC = NO
# If the INLINE_INHERITED_MEMB tag is set to YES, doxygen will show all
# inherited members of a class in the documentation of that class as if those
# members were ordinary class members. Constructors, destructors and assignment
# operators of the base classes will not be shown.
INLINE_INHERITED_MEMB = NO
# If the FULL_PATH_NAMES tag is set to YES then Doxygen will prepend the full
# path before files name in the file list and in the header files. If set
# to NO the shortest path that makes the file name unique will be used.
FULL_PATH_NAMES = NO
# If the FULL_PATH_NAMES tag is set to YES then the STRIP_FROM_PATH tag
# can be used to strip a user-defined part of the path. Stripping is
# only done if one of the specified strings matches the left-hand part of
# the path. The tag can be used to show relative paths in the file list.
# If left blank the directory from which doxygen is run is used as the
# path to strip.
STRIP_FROM_PATH =
# The STRIP_FROM_INC_PATH tag can be used to strip a user-defined part of
# the path mentioned in the documentation of a class, which tells
# the reader which header file to include in order to use a class.
# If left blank only the name of the header file containing the class
# definition is used. Otherwise one should specify the include paths that
# are normally passed to the compiler using the -I flag.
STRIP_FROM_INC_PATH =
# If the SHORT_NAMES tag is set to YES, doxygen will generate much shorter
# (but less readable) file names. This can be useful is your file systems
# doesn't support long names like on DOS, Mac, or CD-ROM.
SHORT_NAMES = NO
# If the JAVADOC_AUTOBRIEF tag is set to YES then Doxygen
# will interpret the first line (until the first dot) of a JavaDoc-style
# comment as the brief description. If set to NO, the JavaDoc
# comments will behave just like the Qt-style comments (thus requiring an
# explicit @brief command for a brief description.
JAVADOC_AUTOBRIEF = YES
# The MULTILINE_CPP_IS_BRIEF tag can be set to YES to make Doxygen
# treat a multi-line C++ special comment block (i.e. a block of //! or ///
# comments) as a brief description. This used to be the default behaviour.
# The new default is to treat a multi-line C++ comment block as a detailed
# description. Set this tag to YES if you prefer the old behaviour instead.
MULTILINE_CPP_IS_BRIEF = NO
# If the DETAILS_AT_TOP tag is set to YES then Doxygen
# will output the detailed description near the top, like JavaDoc.
# If set to NO, the detailed description appears after the member
# documentation.
DETAILS_AT_TOP = NO
# If the INHERIT_DOCS tag is set to YES (the default) then an undocumented
# member inherits the documentation from any documented member that it
# re-implements.
INHERIT_DOCS = YES
# If member grouping is used in the documentation and the DISTRIBUTE_GROUP_DOC
# tag is set to YES, then doxygen will reuse the documentation of the first
# member in the group (if any) for the other members of the group. By default
# all members of a group must be documented explicitly.
DISTRIBUTE_GROUP_DOC = NO
# If the SEPARATE_MEMBER_PAGES tag is set to YES, then doxygen will produce
# a new page for each member. If set to NO, the documentation of a member will
# be part of the file/class/namespace that contains it.
SEPARATE_MEMBER_PAGES = NO
# The TAB_SIZE tag can be used to set the number of spaces in a tab.
# Doxygen uses this value to replace tabs by spaces in code fragments.
TAB_SIZE = 4
# This tag can be used to specify a number of aliases that acts
# as commands in the documentation. An alias has the form "name=value".
# For example adding "sideeffect=\par Side Effects:\n" will allow you to
# put the command \sideeffect (or @sideeffect) in the documentation, which
# will result in a user-defined paragraph with heading "Side Effects:".
# You can put \n's in the value part of an alias to insert newlines.
ALIASES =
# Set the OPTIMIZE_OUTPUT_FOR_C tag to YES if your project consists of C
# sources only. Doxygen will then generate output that is more tailored for C.
# For instance, some of the names that are used will be different. The list
# of all members will be omitted, etc.
OPTIMIZE_OUTPUT_FOR_C = YES
# Set the OPTIMIZE_OUTPUT_JAVA tag to YES if your project consists of Java sources
# only. Doxygen will then generate output that is more tailored for Java.
# For instance, namespaces will be presented as packages, qualified scopes
# will look different, etc.
OPTIMIZE_OUTPUT_JAVA = NO
# Set the SUBGROUPING tag to YES (the default) to allow class member groups of
# the same type (for instance a group of public functions) to be put as a
# subgroup of that type (e.g. under the Public Functions section). Set it to
# NO to prevent subgrouping. Alternatively, this can be done per class using
# the \nosubgrouping command.
SUBGROUPING = YES
#---------------------------------------------------------------------------
# Build related configuration options
#---------------------------------------------------------------------------
# If the EXTRACT_ALL tag is set to YES doxygen will assume all entities in
# documentation are documented, even if no documentation was available.
# Private class members and static file members will be hidden unless
# the EXTRACT_PRIVATE and EXTRACT_STATIC tags are set to YES
EXTRACT_ALL = YES
# If the EXTRACT_PRIVATE tag is set to YES all private members of a class
# will be included in the documentation.
EXTRACT_PRIVATE = NO
# If the EXTRACT_STATIC tag is set to YES all static members of a file
# will be included in the documentation.
EXTRACT_STATIC = NO
# If the EXTRACT_LOCAL_CLASSES tag is set to YES classes (and structs)
# defined locally in source files will be included in the documentation.
# If set to NO only classes defined in header files are included.
EXTRACT_LOCAL_CLASSES = YES
# This flag is only useful for Objective-C code. When set to YES local
# methods, which are defined in the implementation section but not in
# the interface are included in the documentation.
# If set to NO (the default) only methods in the interface are included.
EXTRACT_LOCAL_METHODS = NO
# If the HIDE_UNDOC_MEMBERS tag is set to YES, Doxygen will hide all
# undocumented members of documented classes, files or namespaces.
# If set to NO (the default) these members will be included in the
# various overviews, but no documentation section is generated.
# This option has no effect if EXTRACT_ALL is enabled.
HIDE_UNDOC_MEMBERS = NO
# If the HIDE_UNDOC_CLASSES tag is set to YES, Doxygen will hide all
# undocumented classes that are normally visible in the class hierarchy.
# If set to NO (the default) these classes will be included in the various
# overviews. This option has no effect if EXTRACT_ALL is enabled.
HIDE_UNDOC_CLASSES = NO
# If the HIDE_FRIEND_COMPOUNDS tag is set to YES, Doxygen will hide all
# friend (class|struct|union) declarations.
# If set to NO (the default) these declarations will be included in the
# documentation.
HIDE_FRIEND_COMPOUNDS = NO
# If the HIDE_IN_BODY_DOCS tag is set to YES, Doxygen will hide any
# documentation blocks found inside the body of a function.
# If set to NO (the default) these blocks will be appended to the
# function's detailed documentation block.
HIDE_IN_BODY_DOCS = NO
# The INTERNAL_DOCS tag determines if documentation
# that is typed after a \internal command is included. If the tag is set
# to NO (the default) then the documentation will be excluded.
# Set it to YES to include the internal documentation.
INTERNAL_DOCS = NO
# If the CASE_SENSE_NAMES tag is set to NO then Doxygen will only generate
# file names in lower-case letters. If set to YES upper-case letters are also
# allowed. This is useful if you have classes or files whose names only differ
# in case and if your file system supports case sensitive file names. Windows
# and Mac users are advised to set this option to NO.
CASE_SENSE_NAMES = YES
# If the HIDE_SCOPE_NAMES tag is set to NO (the default) then Doxygen
# will show members with their full class and namespace scopes in the
# documentation. If set to YES the scope will be hidden.
HIDE_SCOPE_NAMES = NO
# If the SHOW_INCLUDE_FILES tag is set to YES (the default) then Doxygen
# will put a list of the files that are included by a file in the documentation
# of that file.
SHOW_INCLUDE_FILES = YES
# If the INLINE_INFO tag is set to YES (the default) then a tag [inline]
# is inserted in the documentation for inline members.
INLINE_INFO = YES
# If the SORT_MEMBER_DOCS tag is set to YES (the default) then doxygen
# will sort the (detailed) documentation of file and class members
# alphabetically by member name. If set to NO the members will appear in
# declaration order.
SORT_MEMBER_DOCS = YES
# If the SORT_BRIEF_DOCS tag is set to YES then doxygen will sort the
# brief documentation of file, namespace and class members alphabetically
# by member name. If set to NO (the default) the members will appear in
# declaration order.
SORT_BRIEF_DOCS = NO
# If the SORT_BY_SCOPE_NAME tag is set to YES, the class list will be
# sorted by fully-qualified names, including namespaces. If set to
# NO (the default), the class list will be sorted only by class name,
# not including the namespace part.
# Note: This option is not very useful if HIDE_SCOPE_NAMES is set to YES.
# Note: This option applies only to the class list, not to the
# alphabetical list.
SORT_BY_SCOPE_NAME = NO
# The GENERATE_TODOLIST tag can be used to enable (YES) or
# disable (NO) the todo list. This list is created by putting \todo
# commands in the documentation.
GENERATE_TODOLIST = YES
# The GENERATE_TESTLIST tag can be used to enable (YES) or
# disable (NO) the test list. This list is created by putting \test
# commands in the documentation.
GENERATE_TESTLIST = YES
# The GENERATE_BUGLIST tag can be used to enable (YES) or
# disable (NO) the bug list. This list is created by putting \bug
# commands in the documentation.
GENERATE_BUGLIST = YES
# The GENERATE_DEPRECATEDLIST tag can be used to enable (YES) or
# disable (NO) the deprecated list. This list is created by putting
# \deprecated commands in the documentation.
GENERATE_DEPRECATEDLIST= YES
# The ENABLED_SECTIONS tag can be used to enable conditional
# documentation sections, marked by \if sectionname ... \endif.
ENABLED_SECTIONS =
# The MAX_INITIALIZER_LINES tag determines the maximum number of lines
# the initial value of a variable or define consists of for it to appear in
# the documentation. If the initializer consists of more lines than specified
# here it will be hidden. Use a value of 0 to hide initializers completely.
# The appearance of the initializer of individual variables and defines in the
# documentation can be controlled using \showinitializer or \hideinitializer
# command in the documentation regardless of this setting.
MAX_INITIALIZER_LINES = 30
# Set the SHOW_USED_FILES tag to NO to disable the list of files generated
# at the bottom of the documentation of classes and structs. If set to YES the
# list will mention the files that were used to generate the documentation.
SHOW_USED_FILES = YES
# If the sources in your project are distributed over multiple directories
# then setting the SHOW_DIRECTORIES tag to YES will show the directory hierarchy
# in the documentation. The default is YES.
SHOW_DIRECTORIES = YES
# The FILE_VERSION_FILTER tag can be used to specify a program or script that
# doxygen should invoke to get the current version for each file (typically from the
# version control system). Doxygen will invoke the program by executing (via
# popen()) the command , where is the value of
# the FILE_VERSION_FILTER tag, and is the name of an input file
# provided by doxygen. Whatever the progam writes to standard output
# is used as the file version. See the manual for examples.
FILE_VERSION_FILTER =
#---------------------------------------------------------------------------
# configuration options related to warning and progress messages
#---------------------------------------------------------------------------
# The QUIET tag can be used to turn on/off the messages that are generated
# by doxygen. Possible values are YES and NO. If left blank NO is used.
QUIET = NO
WARNINGS = YES
WARN_IF_UNDOCUMENTED = YES
WARN_IF_DOC_ERROR = YES
WARN_NO_PARAMDOC = NO
WARN_FORMAT = "$file:$line: $text"
WARN_LOGFILE =
#---------------------------------------------------------------------------
# configuration options related to the input files
#---------------------------------------------------------------------------
# The INPUT tag can be used to specify the files and/or directories that contain
# documented source files. You may enter file names like "myfile.cpp" or
# directories like "/usr/src/myproject". Separate the files or directories
# with spaces.
INPUT =
# If the value of the INPUT tag contains directories, you can use the
# FILE_PATTERNS tag to specify one or more wildcard pattern (like *.cpp
# and *.h) to filter out the source-files in the directories. If left
# blank the following patterns are tested:
# *.c *.cc *.cxx *.cpp *.c++ *.java *.ii *.ixx *.ipp *.i++ *.inl *.h *.hh *.hxx
# *.hpp *.h++ *.idl *.odl *.cs *.php *.php3 *.inc *.m *.mm
FILE_PATTERNS =
# The RECURSIVE tag can be used to turn specify whether or not subdirectories
# should be searched for input files as well. Possible values are YES and NO.
# If left blank NO is used.
RECURSIVE = NO
# The EXCLUDE tag can be used to specify files and/or directories that should
# excluded from the INPUT source files. This way you can easily exclude a
# subdirectory from a directory tree whose root is specified with the INPUT tag.
EXCLUDE =
# The EXCLUDE_SYMLINKS tag can be used select whether or not files or
# directories that are symbolic links (a Unix filesystem feature) are excluded
# from the input.
EXCLUDE_SYMLINKS = NO
# If the value of the INPUT tag contains directories, you can use the
# EXCLUDE_PATTERNS tag to specify one or more wildcard patterns to exclude
# certain files from those directories. Note that the wildcards are matched
# against the file with absolute path, so to exclude all test directories
# for example use the pattern */test/*
EXCLUDE_PATTERNS =
# The EXAMPLE_PATH tag can be used to specify one or more files or
# directories that contain example code fragments that are included (see
# the \include command).
EXAMPLE_PATH =
# If the value of the EXAMPLE_PATH tag contains directories, you can use the
# EXAMPLE_PATTERNS tag to specify one or more wildcard pattern (like *.cpp
# and *.h) to filter out the source-files in the directories. If left
# blank all files are included.
EXAMPLE_PATTERNS =
# If the EXAMPLE_RECURSIVE tag is set to YES then subdirectories will be
# searched for input files to be used with the \include or \dontinclude
# commands irrespective of the value of the RECURSIVE tag.
# Possible values are YES and NO. If left blank NO is used.
EXAMPLE_RECURSIVE = NO
# The IMAGE_PATH tag can be used to specify one or more files or
# directories that contain image that are included in the documentation (see
# the \image command).
IMAGE_PATH =
# The INPUT_FILTER tag can be used to specify a program that doxygen should
# invoke to filter for each input file. Doxygen will invoke the filter program
# by executing (via popen()) the command , where
# is the value of the INPUT_FILTER tag, and is the name of an
# input file. Doxygen will then use the output that the filter program writes
# to standard output. If FILTER_PATTERNS is specified, this tag will be
# ignored.
INPUT_FILTER =
# The FILTER_PATTERNS tag can be used to specify filters on a per file pattern
# basis. Doxygen will compare the file name with each pattern and apply the
# filter if there is a match. The filters are a list of the form:
# pattern=filter (like *.cpp=my_cpp_filter). See INPUT_FILTER for further
# info on how filters are used. If FILTER_PATTERNS is empty, INPUT_FILTER
# is applied to all files.
FILTER_PATTERNS =
# If the FILTER_SOURCE_FILES tag is set to YES, the input filter (if set using
# INPUT_FILTER) will be used to filter the input files when producing source
# files to browse (i.e. when SOURCE_BROWSER is set to YES).
FILTER_SOURCE_FILES = NO
#---------------------------------------------------------------------------
# configuration options related to source browsing
#---------------------------------------------------------------------------
# If the SOURCE_BROWSER tag is set to YES then a list of source files will
# be generated. Documented entities will be cross-referenced with these sources.
# Note: To get rid of all source code in the generated output, make sure also
# VERBATIM_HEADERS is set to NO.
SOURCE_BROWSER = YES
# Setting the INLINE_SOURCES tag to YES will include the body
# of functions and classes directly in the documentation.
INLINE_SOURCES = NO
# Setting the STRIP_CODE_COMMENTS tag to YES (the default) will instruct
# doxygen to hide any special comment blocks from generated source code
# fragments. Normal C and C++ comments will always remain visible.
STRIP_CODE_COMMENTS = YES
# If the REFERENCED_BY_RELATION tag is set to YES (the default)
# then for each documented function all documented
# functions referencing it will be listed.
REFERENCED_BY_RELATION = YES
# If the REFERENCES_RELATION tag is set to YES (the default)
# then for each documented function all documented entities
# called/used by that function will be listed.
REFERENCES_RELATION = YES
# If the USE_HTAGS tag is set to YES then the references to source code
# will point to the HTML generated by the htags(1) tool instead of doxygen
# built-in source browser. The htags tool is part of GNU's global source
# tagging system (see http://www.gnu.org/software/global/global.html). You
# will need version 4.8.6 or higher.
USE_HTAGS = NO
# If the VERBATIM_HEADERS tag is set to YES (the default) then Doxygen
# will generate a verbatim copy of the header file for each class for
# which an include is specified. Set to NO to disable this.
VERBATIM_HEADERS = YES
#---------------------------------------------------------------------------
# configuration options related to the alphabetical class index
#---------------------------------------------------------------------------
# If the ALPHABETICAL_INDEX tag is set to YES, an alphabetical index
# of all compounds will be generated. Enable this if the project
# contains a lot of classes, structs, unions or interfaces.
ALPHABETICAL_INDEX = YES
# If the alphabetical index is enabled (see ALPHABETICAL_INDEX) then
# the COLS_IN_ALPHA_INDEX tag can be used to specify the number of columns
# in which this list will be split (can be a number in the range [1..20])
COLS_IN_ALPHA_INDEX = 5
# In case all classes in a project start with a common prefix, all
# classes will be put under the same header in the alphabetical index.
# The IGNORE_PREFIX tag can be used to specify one or more prefixes that
# should be ignored while generating the index headers.
IGNORE_PREFIX =
#---------------------------------------------------------------------------
# configuration options related to the HTML output
#---------------------------------------------------------------------------
# If the GENERATE_HTML tag is set to YES (the default) Doxygen will
# generate HTML output.
GENERATE_HTML = YES
# The HTML_OUTPUT tag is used to specify where the HTML docs will be put.
# If a relative path is entered the value of OUTPUT_DIRECTORY will be
# put in front of it. If left blank `html' will be used as the default path.
HTML_OUTPUT = html
# The HTML_FILE_EXTENSION tag can be used to specify the file extension for
# each generated HTML page (for example: .htm,.php,.asp). If it is left blank
# doxygen will generate files with .html extension.
HTML_FILE_EXTENSION = .html
# The HTML_HEADER tag can be used to specify a personal HTML header for
# each generated HTML page. If it is left blank doxygen will generate a
# standard header.
HTML_HEADER =
# The HTML_FOOTER tag can be used to specify a personal HTML footer for
# each generated HTML page. If it is left blank doxygen will generate a
# standard footer.
HTML_FOOTER =
# The HTML_STYLESHEET tag can be used to specify a user-defined cascading
# style sheet that is used by each HTML page. It can be used to
# fine-tune the look of the HTML output. If the tag is left blank doxygen
# will generate a default style sheet. Note that doxygen will try to copy
# the style sheet file to the HTML output directory, so don't put your own
# stylesheet in the HTML output directory as well, or it will be erased!
HTML_STYLESHEET =
# If the HTML_ALIGN_MEMBERS tag is set to YES, the members of classes,
# files or namespaces will be aligned in HTML using tables. If set to
# NO a bullet list will be used.
HTML_ALIGN_MEMBERS = YES
# If the GENERATE_HTMLHELP tag is set to YES, additional index files
# will be generated that can be used as input for tools like the
# Microsoft HTML help workshop to generate a compressed HTML help file (.chm)
# of the generated HTML documentation.
GENERATE_HTMLHELP = NO
# If the GENERATE_HTMLHELP tag is set to YES, the CHM_FILE tag can
# be used to specify the file name of the resulting .chm file. You
# can add a path in front of the file if the result should not be
# written to the html output directory.
CHM_FILE =
# If the GENERATE_HTMLHELP tag is set to YES, the HHC_LOCATION tag can
# be used to specify the location (absolute path including file name) of
# the HTML help compiler (hhc.exe). If non-empty doxygen will try to run
# the HTML help compiler on the generated index.hhp.
HHC_LOCATION =
# If the GENERATE_HTMLHELP tag is set to YES, the GENERATE_CHI flag
# controls if a separate .chi index file is generated (YES) or that
# it should be included in the master .chm file (NO).
GENERATE_CHI = NO
# If the GENERATE_HTMLHELP tag is set to YES, the BINARY_TOC flag
# controls whether a binary table of contents is generated (YES) or a
# normal table of contents (NO) in the .chm file.
BINARY_TOC = NO
# The TOC_EXPAND flag can be set to YES to add extra items for group members
# to the contents of the HTML help documentation and to the tree view.
TOC_EXPAND = NO
# The DISABLE_INDEX tag can be used to turn on/off the condensed index at
# top of each HTML page. The value NO (the default) enables the index and
# the value YES disables it.
DISABLE_INDEX = NO
# This tag can be used to set the number of enum values (range [1..20])
# that doxygen will group on one line in the generated HTML documentation.
ENUM_VALUES_PER_LINE = 4
# If the GENERATE_TREEVIEW tag is set to YES, a side panel will be
# generated containing a tree-like index structure (just like the one that
# is generated for HTML Help). For this to work a browser that supports
# JavaScript, DHTML, CSS and frames is required (for instance Mozilla 1.0+,
# Netscape 6.0+, Internet explorer 5.0+, or Konqueror). Windows users are
# probably better off using the HTML help feature.
GENERATE_TREEVIEW = YES
# If the treeview is enabled (see GENERATE_TREEVIEW) then this tag can be
# used to set the initial width (in pixels) of the frame in which the tree
# is shown.
TREEVIEW_WIDTH = 250
#---------------------------------------------------------------------------
# configuration options related to the LaTeX output
#---------------------------------------------------------------------------
GENERATE_LATEX = NO
LATEX_OUTPUT = latex
LATEX_CMD_NAME = latex
MAKEINDEX_CMD_NAME = makeindex
COMPACT_LATEX = NO
# The PAPER_TYPE tag can be used to set the paper type that is used
# by the printer. Possible values are: a4, a4wide, letter, legal and
# executive. If left blank a4wide will be used.
PAPER_TYPE = a4wide
# The EXTRA_PACKAGES tag can be to specify one or more names of LaTeX
# packages that should be included in the LaTeX output.
EXTRA_PACKAGES =
# The LATEX_HEADER tag can be used to specify a personal LaTeX header for
# the generated latex document. The header should contain everything until
# the first chapter. If it is left blank doxygen will generate a
# standard header. Notice: only use this tag if you know what you are doing!
LATEX_HEADER =
# If the PDF_HYPERLINKS tag is set to YES, the LaTeX that is generated
# is prepared for conversion to pdf (using ps2pdf). The pdf file will
# contain links (just like the HTML output) instead of page references
# This makes the output suitable for online browsing using a pdf viewer.
PDF_HYPERLINKS = NO
# If the USE_PDFLATEX tag is set to YES, pdflatex will be used instead of
# plain latex in the generated Makefile. Set this option to YES to get a
# higher quality PDF documentation.
USE_PDFLATEX = NO
# If the LATEX_BATCHMODE tag is set to YES, doxygen will add the \\batchmode.
# command to the generated LaTeX files. This will instruct LaTeX to keep
# running if errors occur, instead of asking the user for help.
# This option is also used when generating formulas in HTML.
LATEX_BATCHMODE = NO
# If LATEX_HIDE_INDICES is set to YES then doxygen will not
# include the index chapters (such as File Index, Compound Index, etc.)
# in the output.
LATEX_HIDE_INDICES = NO
#---------------------------------------------------------------------------
# configuration options related to the RTF output
#---------------------------------------------------------------------------
GENERATE_RTF = NO
RTF_OUTPUT = rtf
COMPACT_RTF = NO
RTF_HYPERLINKS = NO
RTF_STYLESHEET_FILE =
RTF_EXTENSIONS_FILE =
#---------------------------------------------------------------------------
# configuration options related to the man page output
#---------------------------------------------------------------------------
# If the GENERATE_MAN tag is set to YES (the default) Doxygen will
# generate man pages
GENERATE_MAN = NO
# The MAN_OUTPUT tag is used to specify where the man pages will be put.
# If a relative path is entered the value of OUTPUT_DIRECTORY will be
# put in front of it. If left blank `man' will be used as the default path.
MAN_OUTPUT = man
# The MAN_EXTENSION tag determines the extension that is added to
# the generated man pages (default is the subroutine's section .3)
MAN_EXTENSION = .3
# If the MAN_LINKS tag is set to YES and Doxygen generates man output,
# then it will generate one additional man file for each entity
# documented in the real man page(s). These additional files
# only source the real man page, but without them the man command
# would be unable to find the correct page. The default is NO.
MAN_LINKS = NO
#---------------------------------------------------------------------------
# configuration options related to the XML output
#---------------------------------------------------------------------------
GENERATE_XML = NO
XML_OUTPUT = xml
XML_SCHEMA =
XML_DTD =
XML_PROGRAMLISTING = YES
#---------------------------------------------------------------------------
# configuration options for the AutoGen Definitions output
#---------------------------------------------------------------------------
# If the GENERATE_AUTOGEN_DEF tag is set to YES Doxygen will
# generate an AutoGen Definitions (see autogen.sf.net) file
# that captures the structure of the code including all
# documentation. Note that this feature is still experimental
# and incomplete at the moment.
GENERATE_AUTOGEN_DEF = NO
#---------------------------------------------------------------------------
# configuration options related to the Perl module output
#---------------------------------------------------------------------------
# If the GENERATE_PERLMOD tag is set to YES Doxygen will
# generate a Perl module file that captures the structure of
# the code including all documentation. Note that this
# feature is still experimental and incomplete at the
# moment.
GENERATE_PERLMOD = NO
# If the PERLMOD_LATEX tag is set to YES Doxygen will generate
# the necessary Makefile rules, Perl scripts and LaTeX code to be able
# to generate PDF and DVI output from the Perl module output.
PERLMOD_LATEX = NO
# If the PERLMOD_PRETTY tag is set to YES the Perl module output will be
# nicely formatted so it can be parsed by a human reader. This is useful
# if you want to understand what is going on. On the other hand, if this
# tag is set to NO the size of the Perl module output will be much smaller
# and Perl will parse it just the same.
PERLMOD_PRETTY = YES
# The names of the make variables in the generated doxyrules.make file
# are prefixed with the string contained in PERLMOD_MAKEVAR_PREFIX.
# This is useful so different doxyrules.make files included by the same
# Makefile don't overwrite each other's variables.
PERLMOD_MAKEVAR_PREFIX =
#---------------------------------------------------------------------------
# Configuration options related to the preprocessor
#---------------------------------------------------------------------------
# If the ENABLE_PREPROCESSING tag is set to YES (the default) Doxygen will
# evaluate all C-preprocessor directives found in the sources and include
# files.
ENABLE_PREPROCESSING = YES
# If the MACRO_EXPANSION tag is set to YES Doxygen will expand all macro
# names in the source code. If set to NO (the default) only conditional
# compilation will be performed. Macro expansion can be done in a controlled
# way by setting EXPAND_ONLY_PREDEF to YES.
MACRO_EXPANSION = NO
# If the EXPAND_ONLY_PREDEF and MACRO_EXPANSION tags are both set to YES
# then the macro expansion is limited to the macros specified with the
# PREDEFINED and EXPAND_AS_PREDEFINED tags.
EXPAND_ONLY_PREDEF = NO
# If the SEARCH_INCLUDES tag is set to YES (the default) the includes files
# in the INCLUDE_PATH (see below) will be search if a #include is found.
SEARCH_INCLUDES = YES
# The INCLUDE_PATH tag can be used to specify one or more directories that
# contain include files that are not input files but should be processed by
# the preprocessor.
INCLUDE_PATH =
# You can use the INCLUDE_FILE_PATTERNS tag to specify one or more wildcard
# patterns (like *.h and *.hpp) to filter out the header-files in the
# directories. If left blank, the patterns specified with FILE_PATTERNS will
# be used.
INCLUDE_FILE_PATTERNS =
# The PREDEFINED tag can be used to specify one or more macro names that
# are defined before the preprocessor is started (similar to the -D option of
# gcc). The argument of the tag is a list of macros of the form: name
# or name=definition (no spaces). If the definition and the = are
# omitted =1 is assumed. To prevent a macro definition from being
# undefined via #undef or recursively expanded use the := operator
# instead of the = operator.
PREDEFINED =
# If the MACRO_EXPANSION and EXPAND_ONLY_PREDEF tags are set to YES then
# this tag can be used to specify a list of macro names that should be expanded.
# The macro definition that is found in the sources will be used.
# Use the PREDEFINED tag if you want to use a different macro definition.
EXPAND_AS_DEFINED =
# If the SKIP_FUNCTION_MACROS tag is set to YES (the default) then
# doxygen's preprocessor will remove all function-like macros that are alone
# on a line, have an all uppercase name, and do not end with a semicolon. Such
# function macros are typically used for boiler-plate code, and will confuse
# the parser if not removed.
SKIP_FUNCTION_MACROS = YES
#---------------------------------------------------------------------------
# Configuration::additions related to external references
#---------------------------------------------------------------------------
# The TAGFILES option can be used to specify one or more tagfiles.
# Optionally an initial location of the external documentation
# can be added for each tagfile. The format of a tag file without
# this location is as follows:
# TAGFILES = file1 file2 ...
# Adding location for the tag files is done as follows:
# TAGFILES = file1=loc1 "file2 = loc2" ...
# where "loc1" and "loc2" can be relative or absolute paths or
# URLs. If a location is present for each tag, the installdox tool
# does not have to be run to correct the links.
# Note that each tag file must have a unique name
# (where the name does NOT include the path)
# If a tag file is not located in the directory in which doxygen
# is run, you must also specify the path to the tagfile here.
TAGFILES =
# When a file name is specified after GENERATE_TAGFILE, doxygen will create
# a tag file that is based on the input files it reads.
GENERATE_TAGFILE =
# If the ALLEXTERNALS tag is set to YES all external classes will be listed
# in the class index. If set to NO only the inherited external classes
# will be listed.
ALLEXTERNALS = NO
# If the EXTERNAL_GROUPS tag is set to YES all external groups will be listed
# in the modules index. If set to NO, only the current project's groups will
# be listed.
EXTERNAL_GROUPS = YES
# The PERL_PATH should be the absolute path and name of the perl script
# interpreter (i.e. the result of `which perl').
PERL_PATH = /usr/bin/perl
#---------------------------------------------------------------------------
# Configuration options related to the dot tool
#---------------------------------------------------------------------------
# If the CLASS_DIAGRAMS tag is set to YES (the default) Doxygen will
# generate a inheritance diagram (in HTML, RTF and LaTeX) for classes with base
# or super classes. Setting the tag to NO turns the diagrams off. Note that
# this option is superseded by the HAVE_DOT option below. This is only a
# fallback. It is recommended to install and use dot, since it yields more
# powerful graphs.
CLASS_DIAGRAMS = YES
# If set to YES, the inheritance and collaboration graphs will hide
# inheritance and usage relations if the target is undocumented
# or is not a class.
HIDE_UNDOC_RELATIONS = YES
# If you set the HAVE_DOT tag to YES then doxygen will assume the dot tool is
# available from the path. This tool is part of Graphviz, a graph visualization
# toolkit from AT&T and Lucent Bell Labs. The other options in this section
# have no effect if this option is set to NO (the default)
HAVE_DOT = YES
# If the CLASS_GRAPH and HAVE_DOT tags are set to YES then doxygen
# will generate a graph for each documented class showing the direct and
# indirect inheritance relations. Setting this tag to YES will force the
# the CLASS_DIAGRAMS tag to NO.
CLASS_GRAPH = YES
# If the COLLABORATION_GRAPH and HAVE_DOT tags are set to YES then doxygen
# will generate a graph for each documented class showing the direct and
# indirect implementation dependencies (inheritance, containment, and
# class references variables) of the class with other documented classes.
COLLABORATION_GRAPH = YES
# If the GROUP_GRAPHS and HAVE_DOT tags are set to YES then doxygen
# will generate a graph for groups, showing the direct groups dependencies
GROUP_GRAPHS = YES
# If the UML_LOOK tag is set to YES doxygen will generate inheritance and
# collaboration diagrams in a style similar to the OMG's Unified Modeling
# Language.
UML_LOOK = NO
# If set to YES, the inheritance and collaboration graphs will show the
# relations between templates and their instances.
TEMPLATE_RELATIONS = YES
# If the ENABLE_PREPROCESSING, SEARCH_INCLUDES, INCLUDE_GRAPH, and HAVE_DOT
# tags are set to YES then doxygen will generate a graph for each documented
# file showing the direct and indirect include dependencies of the file with
# other documented files.
INCLUDE_GRAPH = YES
# If the ENABLE_PREPROCESSING, SEARCH_INCLUDES, INCLUDED_BY_GRAPH, and
# HAVE_DOT tags are set to YES then doxygen will generate a graph for each
# documented header file showing the documented files that directly or
# indirectly include this file.
INCLUDED_BY_GRAPH = YES
# If the CALL_GRAPH and HAVE_DOT tags are set to YES then doxygen will
# generate a call dependency graph for every global function or class method.
# Note that enabling this option will significantly increase the time of a run.
# So in most cases it will be better to enable call graphs for selected
# functions only using the \callgraph command.
CALL_GRAPH = NO
# If the GRAPHICAL_HIERARCHY and HAVE_DOT tags are set to YES then doxygen
# will graphical hierarchy of all classes instead of a textual one.
GRAPHICAL_HIERARCHY = YES
# If the DIRECTORY_GRAPH, SHOW_DIRECTORIES and HAVE_DOT tags are set to YES
# then doxygen will show the dependencies a directory has on other directories
# in a graphical way. The dependency relations are determined by the #include
# relations between the files in the directories.
DIRECTORY_GRAPH = YES
# The DOT_IMAGE_FORMAT tag can be used to set the image format of the images
# generated by dot. Possible values are png, jpg, or gif
# If left blank png will be used.
DOT_IMAGE_FORMAT = png
# The tag DOT_PATH can be used to specify the path where the dot tool can be
# found. If left blank, it is assumed the dot tool can be found in the path.
DOT_PATH =
# The DOTFILE_DIRS tag can be used to specify one or more directories that
# contain dot files that are included in the documentation (see the
# \dotfile command).
DOTFILE_DIRS =
# The MAX_DOT_GRAPH_WIDTH tag can be used to set the maximum allowed width
# (in pixels) of the graphs generated by dot. If a graph becomes larger than
# this value, doxygen will try to truncate the graph, so that it fits within
# the specified constraint. Beware that most browsers cannot cope with very
# large images.
MAX_DOT_GRAPH_WIDTH = 1024
# The MAX_DOT_GRAPH_HEIGHT tag can be used to set the maximum allows height
# (in pixels) of the graphs generated by dot. If a graph becomes larger than
# this value, doxygen will try to truncate the graph, so that it fits within
# the specified constraint. Beware that most browsers cannot cope with very
# large images.
MAX_DOT_GRAPH_HEIGHT = 1024
# The MAX_DOT_GRAPH_DEPTH tag can be used to set the maximum depth of the
# graphs generated by dot. A depth value of 3 means that only nodes reachable
# from the root by following a path via at most 3 edges will be shown. Nodes
# that lay further from the root node will be omitted. Note that setting this
# option to 1 or 2 may greatly reduce the computation time needed for large
# code bases. Also note that a graph may be further truncated if the graph's
# image dimensions are not sufficient to fit the graph (see MAX_DOT_GRAPH_WIDTH
# and MAX_DOT_GRAPH_HEIGHT). If 0 is used for the depth value (the default),
# the graph is not depth-constrained.
MAX_DOT_GRAPH_DEPTH = 0
# Set the DOT_TRANSPARENT tag to YES to generate images with a transparent
# background. This is disabled by default, which results in a white background.
# Warning: Depending on the platform used, enabling this option may lead to
# badly anti-aliased labels on the edges of a graph (i.e. they become hard to
# read).
DOT_TRANSPARENT = NO
# Set the DOT_MULTI_TARGETS tag to YES allow dot to generate multiple output
# files in one run (i.e. multiple -o and -T options on the command line). This
# makes dot run faster, but since only newer versions of dot (>1.8.10)
# support this, this feature is disabled by default.
DOT_MULTI_TARGETS = NO
# If the GENERATE_LEGEND tag is set to YES (the default) Doxygen will
# generate a legend page explaining the meaning of the various boxes and
# arrows in the dot generated graphs.
GENERATE_LEGEND = YES
# If the DOT_CLEANUP tag is set to YES (the default) Doxygen will
# remove the intermediate dot files that are used to generate
# the various graphs.
DOT_CLEANUP = YES
#---------------------------------------------------------------------------
# Configuration::additions related to the search engine
#---------------------------------------------------------------------------
# The SEARCHENGINE tag specifies whether or not a search engine should be
# used. If set to NO the values of all tags below this one will be ignored.
SEARCHENGINE = YES
Changed from default: (new values shown below and bold in above listing)
- PROJECT_NAME = "Project XXX" - Specify a project name.
- OUTPUT_DIRECTORY = documents - Specify a documentation directory for the processed results.
- FULL_PATH_NAMES = NO - Looks cleaner this way. Set to YES for code which has a sensible path hierarchy.
- JAVADOC_AUTOBRIEF = YES - Don't need explicit "brief" tag
- HIDE_UNDOC_CLASSES = NO - I let doxygen document everything
- GENERATE_LATEX = NO - I use HTML docs and have no need for Latex
- TAB_SIZE = 4 - Default is 8
- OPTIMIZE_OUTPUT_FOR_C = YES - For C and C++ source code
- BUILTIN_STL_SUPPORT = YES - Only available in newer versions of dOxygen
- EXTRACT_ALL = YES
- EXTRACT_LOCAL_CLASSES = YES
- RECURSIVE = YES - Search subdirectories
- SOURCE_BROWSER = YES - List source files
- ALPHABETICAL_INDEX = YES - Generate alphabetic index of classes, structs, unions
- GENERATE_TREEVIEW = YES - Generate side panel nav tree (html frame)
- TEMPLATE_RELATIONS = YES - Show inheritance relationship for templates
- SEARCHENGINE = YES - Creates local search facility.
- FILE_PATTERNS = *.cc *.h *.cpp *.hpp - specify file suffixes to document. I leave it blank to take the default.
- REFERENCED_BY_RELATION = YES - document all entities associated with functions documented
If generating an HTML file, add:
GENERATE_HTML = YES HTML_OUTPUT = html HTML_FILE_EXTENSION = .html HTML_HEADER = HTML_FOOTER = HTML_STYLESHEET = HTML_ALIGN_MEMBERS = YES DISABLE_INDEX = NO
If generating an RTF file, add:
GENERATE_RTF = YES RTF_OUTPUT = rtf COMPACT_RTF = NO RTF_HYPERLINKS = NO RTF_STYLESHEET_FILE = RTF_EXTENSIONS_FILE =
Generate UML class diagrams: (Uses Graphviz)
CLASS_DIAGRAMS = YES HAVE_DOT = YES CLASS_GRAPH = YES COLLABORATION_GRAPH = YES GROUP_GRAPHS = YES UML_LOOK = NO TEMPLATE_RELATIONS = YES INCLUDE_GRAPH = YES INCLUDED_BY_GRAPH = YES CALL_GRAPH = YES CALLER_GRAPH = YES GRAPHICAL_HIERARCHY = YES DIRECTORY_GRAPH = YES DOT_MULTI_TARGETS = YES
If you are running dOxygen against a large software project with large complex classes, one may want to turn off the "COLLABORATION_GRAPH" as it may include an overwhelming number of references.
Note: Graphviz RPMs are available from http://pkgs.repoforge.org/graphviz/
[Potential Pitfall]: If you get the following Graphviz error from running dOxygen:
Error: Layout was not done. Missing layout plugins?Fix: After installation you may have to generate the appropriate plugins configuration by issuing the command (as root) "dot -c"
DOxygen GUI wizard configuration tool: doxywizard
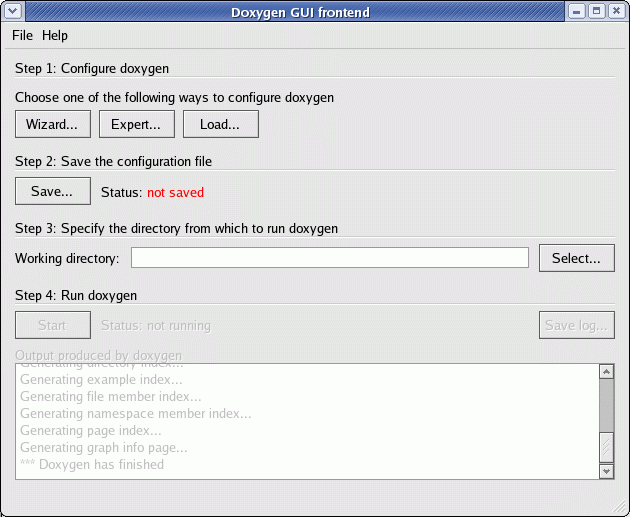
Panel created by selecting "Wizard ...":
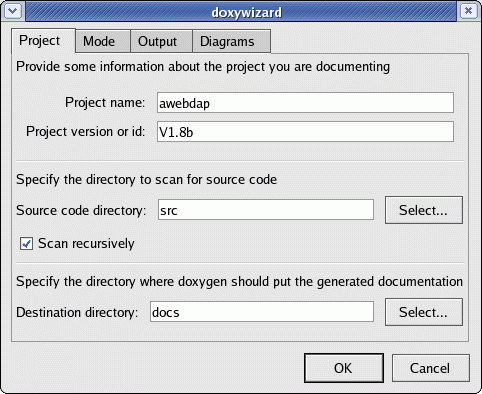
This GUI tools allows one to set preferences with a point and click interface. I find that editing the default file generated by dOxygen is actually more user friendly as it has informative comments explaining each directive.
The "doxywizard" GUI tool is included in the Red Hat/Fedora RPM package "doxygen-doxywizard".
Run DOxygen: doxygen project-name.cfg
This will generate the sub-directory html/ which will contain the documentation generated. Load the file html/index.html in your web browser to view software documentation generated.
Man pages:
Notes: Latex math formulas can also be embebded to generate output for the HTML page. DOxygen also has an interface to Graphviz to generate a C++ inheritance diagram by generating a Graphviz "dot file".
dOxygen is very configurable and allows one to choose tag styles (Qt,Javadoc,dOxygen legacy. These examples show Javadoc style tags), C macro substitution and link to external documentation. dOxygen can generate man pages, HTML documents, XML files and RTF files
dOxygen and C++ STL:
When used in conjunction with Graphviz, dOxygen will generate small UML class diagrams embeded within the documentation. There are two methods to support inclusion of C++ STL:- Include a STL definitions file so dOxygen can display inheritance diagrams which include STL. Place the
file dummySTL.H [cached]
in the directory with your source code before running dOxygen.
No references are required within your code. DOxygen will read the file and
use its definitions to display a more complete class diagram.
- Turn on the built-in support for C++ STL:
Default is "NO".
# If you use STL classes (i.e. std::string, std::vector, etc.) but do not want to # include (a tag file for) the STL sources as input, then you should # set this tag to YES in order to let doxygen match functions declarations and # definitions whose arguments contain STL classes (e.g. func(std::string); v.s. # func(std::string) {}). This also make the inheritance and collaboration # diagrams that involve STL classes more complete and accurate. BUILTIN_STL_SUPPORT = YES
dOxygen and the vim editor:
Vim can perform sytax highlighting (and thus syntax checking). Turn this feature on by making the following entry in the file $HOME/.vimrc :syntax on
let g:load_doxygen_syntax=1
- Parasoft Code Wizard: Coding standards enforcement.
Parasoft.com: CodeWizard home page - Checkstyle: Java code style checker
CheckStyle home page - GNU C++ compiler: g++
Use the command line option -Weffc++ to warn of style violations not in accordance with the following Meyers "Effective C++" coding practices as outlined in the book of the same name:- Item 11: Define a copy constructor and an assignment operator for classes with dynamically allocated memory.
- Item 12: Prefer initialization to assignment in constructors.
- Item 14: Make destructors virtual in base classes.
- Item 15: Have "operator=" return a reference to *this.
- Item 23: Don’t try to return a reference when you must return an object.
- Item 6: Distinguish between prefix and postfix forms of increment and decrement operators.
- Item 7: Never overload "&&", "││", or ",".
Peer review of code during the developemnt process is a healthy step for the empowerment of communication within the software team and is a step to promote software source code quality. Peer reviews should look for:
- Header: license and/or copyright information.
- Comments: adequate explanation, units of measurement. Use of dOxygen tags: comments for each function, function arguments (in/out), ...
- Adherance to coding standards: variable naming, indentation, bracket style, ...
- Use of standard APIs: Don't reinvent and add code maintenance.
- Use of standards: file format standards (i.e. log file formats), ISO or ANSI standards.
- Error checking and handling. Data integrity checks: range checks.
- Resource leaks: memory, database connections, files, sockets, ... freed for each logic path including error handling.
(See the YoLinux.com memory corruption and memory leaks tutorial) - Security: buffer exploits, clear text network communications, ....
- Thread safe: global variables.
- Logic and control structures: infinite loop conditions, correct loop counters, variables initialized before being used, math/algorithms, ...
- Performance: memory, wasted operations, synchronous calls....
- Regression tests including bad data and errors.
- Subversion Best Practices - YoLinux.com best practices guide for software development with the Subversion Change Management system.
- The Ellemtel Telecommunications System Laboratoris C++ Coding Rules and Recommendations - By Mats Henricson and Erik Nyquist. (Original translation from Swedish by Joseph Supanich)
- Google C++ style guide
- Carnegie Mellon SEI CERT: C Secure Coding Standards
- Carnegie Mellon SEI CERT: C++ Secure Coding Standards
- C++ Coding Standard - by Todd Hoff
- Coding Standards - by Christophe Pierret
- IEEE: SESC - Software Engineering Standards Comittee
- Geotechnical Software Services C++ Programming Style Guidelines
- YoLinux.com: Using emacs to beautify your code to Ellemtel (or other) coding standards
 Books:
Books:
 |
Code Complete: A Practical Handbook of Software Construction
by Steve C. McConnell ISBN #0735619670, Microsoft Press 2nd edition (June 2004)
|

|
 |
Exceptional C++: 47 Engineering Puzzles, Programming Problems and Solutions
by Herb Sutter ISBN #0201615622, Addison-Wesley Professional Advanced C++ features and STL.
|
|
 |
More Exceptional C++
by Herb Sutter ISBN #020170434X, Addison-Wesley Professional
|
|
 |
Exceptional C++ Style
by Herb Sutter ISBN #0201760428, Addison-Wesley Professional
|
|
 |
C++ Coding StandardsL 101 Rules, Guidelines and Best Practices
by Herb Sutter and Andrei Alexandrescu ISBN #0321113586, Addison-Wesley Professional
|
|
 |
Effective C++: 50 Specific Ways to Improve Your Programs and Design (2nd Edition)
by Scott Meyers ISBN #0201924889, Addison-Wesley Professional
|
|
 |
More Effective C++: 35 New Ways to improve your Programs and Designs
by Scott Meyers ISBN #020163371X, Addison-Wesley Professional
|
|
 |
C++ How to Program
by Harvey M. Deitel, Paul J. Deitel ISBN #0131857576, Prentice Hall Fifth edition. The first edition of this book (and Professor Sheely at UTA) taught me to program C++. It is complete and covers all the nuances of the C++ language. It also has good code examples. Good for both learning and reference. |
|
 |
"Embedded C Coding Standard"
by Michael Barr October 2008 ISBN #1442164824, Netrino Institute; 1st edition C coding standard to minimize bugs, improve maintainability and portability. |
|
 |
"CERT C Secure Coding Standard"
by Robert C. Seacord October 2008 ISBN #0321563212, Addison-Wesley Professional; 1 edition Work and reference material created by staff at the Sofware Engineering Institute of Carnegie Mellon. Covers root causes of software vulnerabilities in C and prioritizes them by severity, likelihood of exploitation, and remediation costs. Coding examples. |
|